Hello world! :^) it’s been a long time.
I spent some time going deep into Apache’s internals - reading source code, tracing request paths, figuring out how the whole thing is wired together. I ended up writing a 9-chapter series that covers Apache’s architecture from the ground up. It’s the guide I wish existed when I started.
Along the way I also built a fuzzing framework on top of LLVM’s tooling - LibFuzzer for the engine, sanitizers for bug detection, source-based coverage, and eventually a custom LLVM pass that walks the call graph over bitcode. Once you start pulling on the LLVM thread it kind of takes over the whole project.
Here’s the full chapter list:
- Introduction to Apache Architecture
- APR - Apache Portable Runtime
- Memory Management and Pools
- The Configuration System
- MPM - Multi-Processing Modules
- The Hook System
- Filters and Bucket Brigades
- Request Processing Pipeline
- Module Anatomy
apatchy
Back in 2022, I wrote about fuzzing Apache with AFL++. The setup worked, but looking back at it - the whole thing was held together with duct tape. Hot-patching source with python regex, redirecting logs to /dev/null so the machine doesn’t eat itself, killing my ec2 multiple times. It was fun, but it was not something I could hand to someone else and say “here, go fuzz Apache modules with this”.
So I rewrote the whole thing from scratch. Meet apatchy - an in-process fuzzing framework for Apache HTTPD.
What changed
The 2022 setup was essentially: compile Apache with AFL instrumentation, spawn a thread that shoves stdin into a socket, pray that the stability doesn’t tank. If you wanted to fuzz a different module, you had to re-do a bunch of manual steps. Persistent fuzzing helped with speed, but the architecture was fundamentally limited - you’re still going through the full network stack.
apatchy takes a completely different approach. The entire stack is built on clang/LLVM - LibFuzzer as the fuzzing engine, ASan/UBSan for runtime bug detection, SanCov for edge coverage, llvm-cov for coverage reports, and LLVM bitcode for static analysis. Instead of faking network traffic, it replaces Apache’s socket layer with custom I/O filters. The fuzzer feeds raw bytes directly into the same code paths that handle real HTTP requests - parsing, hooks, filters, handlers - all without touching a socket. This means:
- No
desock.sohacks - No spawning threads to create internal connections
- No network I/O overhead at all
The whole request pipeline runs in-process. You get the real Apache code paths with none of the socket baggage.
How it actually works
The core is a custom Apache module (fuzz_common.c) that hooks into the bucket brigade system. When LibFuzzer hands us a buffer, we wrap it in an in-memory bucket and inject it through Apache’s input filter chain. A pre_connection hook sets up a fake connection with a dummy socket so all module hooks still fire. From Apache’s perspective, it’s a normal request - ap_read_request, handlers, output filters, the whole thing. Init (config parsing, module registration, child_init) runs once, then we just keep replaying inputs.
For structure-aware fuzzing, each harness has a .proto file + a converter that assembles valid-ish HTTP requests from protobuf messages. The mutator understands the structure, so it generates requests that actually reach deep into module logic instead of just throwing random bytes at the parser. Currently there are harnesses for mod_session_crypto, mod_rewrite, mod_proxy_uwsgi, multipart form-data, and generic HTTP.
The build system
One thing that annoyed me about the old project was how fragile the build was. Apache’s ./configure is already painful, and when you add sanitizers, coverage flags, and fuzzer instrumentation on top, it gets ugly fast. Different Apache versions have different compiler flag requirements, OpenSSL 3.0 deprecated a bunch of APIs, older versions trigger strict-prototype warnings - it’s a mess.
apatchy handles all of this with a multi-tree build system:
- vanilla - base Apache build with your chosen sanitizers (ASan, UBSan, etc.)
- lf (libfuzzer) - inherits sanitizer flags, adds SanCov instrumentation
- cov (coverage) - source-based coverage with profile instrumentation
Each tree is built from the same source but with different compiler flags. The compat system detects your Apache version and automatically applies the right workarounds (OpenSSL deprecation suppressions, prototype warning fixes, etc). No more manually patching compiler flags per version.
The whole flow is driven by the apatchy CLI:
apatchy download --version 2.4.66
apatchy configure --asan --ubsan
apatchy make --tree vanilla
apatchy make --tree lf
apatchy link --harness mod_fuzzy_proto_session
apatchy fuzz --config configs/session-coverage.conf --seed-dir fuzz-seeds/session/Coverage + Introspection
After a fuzzing campaign, you probably want to know what you actually hit. apatchy builds a coverage tree, replays your corpus through it, and generates an HTML report via llvm-cov. Standard stuff.
The part I’m more excited about is the introspector. It’s a custom LLVM tool (written in C++) that loads the combined bitcode of the entire Apache build and walks the call graph from your entry functions. It builds a recursive call tree with per-function metadata: basic block counts, instruction counts, source locations. Then it dumps everything to JSON.
There’s a web UI (React/TypeScript) that loads this JSON and gives you an interactive call tree overlaid with coverage data. You can see exactly which functions got hit, how deep into the call graph your fuzzer reached, and where the blind spots are. Crash events show up as red dots on the coverage graph.
This is genuinely useful for figuring out where to focus next. Instead of guessing which code paths you’re missing, you can look at the call tree and see “ok, this branch of session_crypto_decode never gets reached because my proto doesn’t generate the right cookie format” - and then fix your harness accordingly.
apatchy coverage report --with-introspect --harness mod_fuzzy_proto_session
apatchy introspect --entry session_crypto_decode,session_crypto_encode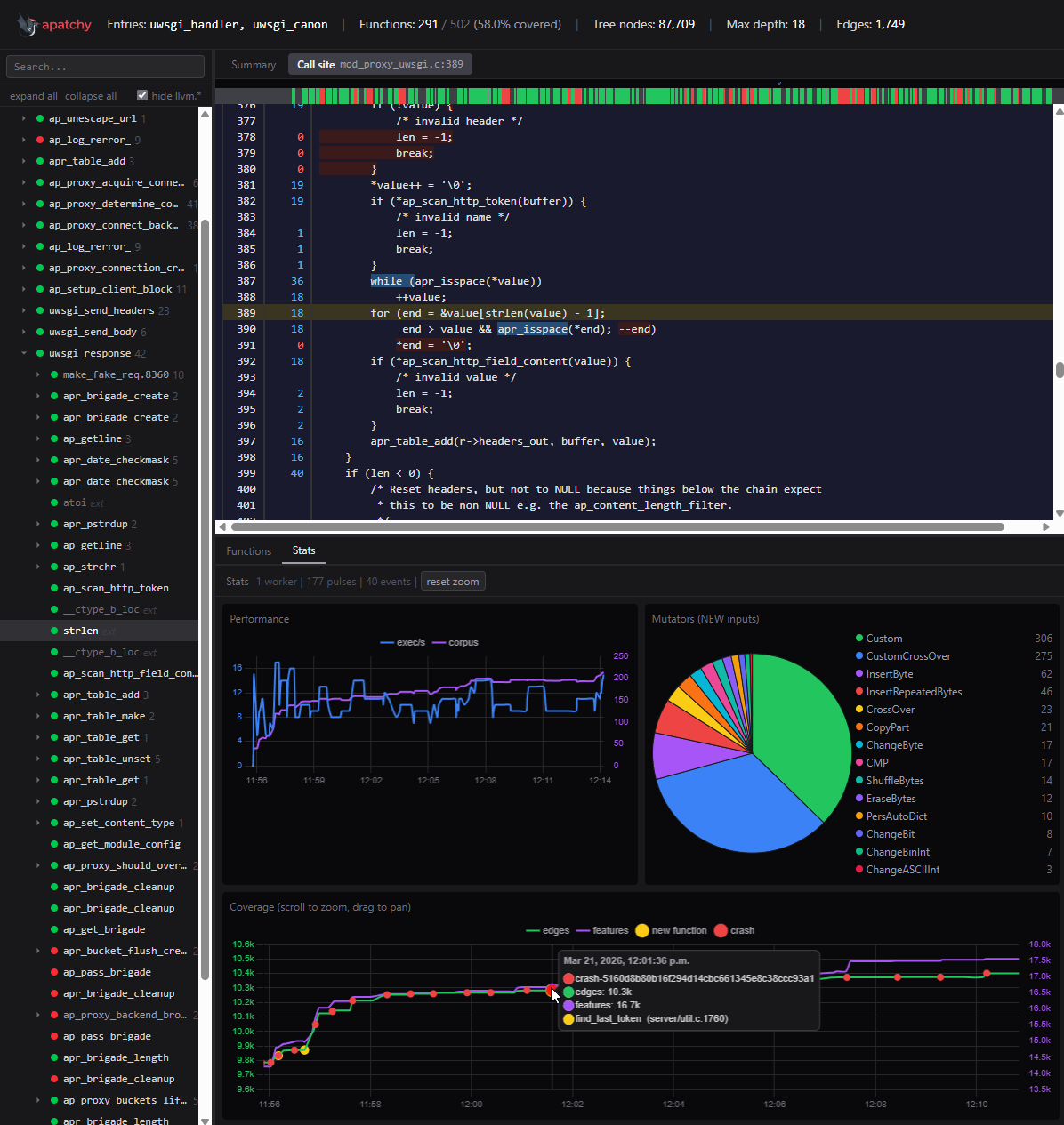
Bug reproduction
apatchy also has a 1day reproduction system. Each bug is described in a bug.toml manifest:
[bug]
id = "CVE-XXXX-XXXXX"
version = "2.4.X"
modules = ["mod_session_crypto"]
type = "heap-buffer-overflow"
[reproduce]
harness = "mod_fuzzy_proto_session"
timeout = 30It downloads the right Apache version, configures the right sanitizers, links the right harness, and replays the crash. Useful for verifying fixes and for understanding how known bugs manifest under different sanitizer configurations.
Current state
The framework is still in alpha. It works and I use it regularly, but expect rough edges. The docs are live at pwner.gg/apatchy but still incomplete - the CLI needs more love and there are parts of the documentation I haven’t gotten around to writing yet.
Things I want to add/improve:
- More harnesses for other Apache modules
- AFL++ engine support (currently LibFuzzer only)
- Better seed generation from grammar files
- More comprehensive docs
Contributing
The easiest way to contribute is by adding Apache configurations. Every new config file means new code paths getting exercised - different module combinations, different directive setups, different edge cases. You don’t need to write C or understand LibFuzzer internals to make an impact here. If you know how to configure Apache, you can help find bugs.
What’s useful:
- Configs that exercise modules we don’t have harnesses for yet
- Unusual directive combinations that might trigger weird interactions
- Real-world configs (sanitized) that reflect how Apache is actually deployed
Drop a PR or open an issue at github.com/0xbigshaq/apatchy. Let’s find some bugs together.